A serious 30-day AI executive assistant pilot is not a miniature transformation program. It is a controlled operating test for a small number of executive workflows. The goal is to prove that the system can fit into the executive office without creating hidden review burden, unclear ownership, or governance risk. That means the pilot should stay narrow: one sponsor, one named operator, 2-4 workflows, explicit exclusions, a fixed review rhythm, and a locked day-30 decision. McKinsey continues to show that adoption is broad but scaled value is harder, while Anthropic recommends starting with the simplest workable system and only adding complexity when it clearly improves outcomes.
This article is intentionally about how to run the pilot operationally. If you need the finance and measurement model instead, go to How to Measure ROI for an AI Executive Assistant in the First 30 Days. If you are earlier in the journey, start with AI Executive Assistant and AI Chief of Staff. If you are already planning review mechanics, pair this guide with approval workflows for executives.
The pilot should answer five operational questions:
- Can the assistant support a small number of executive workflows without creating chaos?
- Are outputs reviewable enough that humans are editing, not rebuilding?
- Are approvals, escalations, and logs behaving the way the office intended?
- Can the executive office sustain the daily operating rhythm required to use the system?
- Is there enough clean evidence to justify a go, extend, or no-go decision?
That is a narrower standard than "did the demo look good?" and a more useful one than "did the model seem smart?" OpenAI's guide to building agents emphasizes clear success criteria, defined evaluations, and combining automation with human judgment. NIST's Generative AI Profile and the OECD's workplace AI guidance reinforce the same point: value only counts if accountability and oversight still work.
By day 30, a good pilot should let the team say:
- the workflows stayed inside the agreed scope
- the review queue stayed understandable and governable
- sensitive items were escalated rather than improvised through
- the executive office could imagine operating this way on purpose, not only under pilot pressure
The cleanest pilots begin with a short written charter. Keep it brief, but explicit.
| Charter item | Recommended default | Why it matters |
|---|
| Sponsor | One executive sponsor | Someone must own the final decision at day 30 |
| Operator | One EA, chief of staff, or delegate | Someone must clear and manage the queue every business day |
| Workflow count | 2-4 workflows | Enough repetition to learn, not enough complexity to blur the signal |
| Pilot length | 30 calendar days | Long enough to establish habit, short enough to force a real decision |
| Review rule | Approval-first for consequential external action | Prevents month-one proof from turning into autonomy risk |
| Exclusions | Legal, HR, board, investor, PR, payments | Keeps the test inside reversible, learnable lanes |
| Decision date | Fixed before kickoff | Prevents an indefinite "pilot" that never has to prove anything |
For most teams, the best month-one workflows are:
- daily brief creation
- meeting prep
- scheduling proposals
- low-risk email drafting
- follow-up drafting after meetings
These are good pilot lanes because they are frequent, reviewable, and easy to observe. They also align with the operating-pressure story in Microsoft's 2025 Work Trend Index: leaders want more leverage, but they still have to decide the right human-agent ratio for real work.
Weak pilots often fail because everyone likes the idea, but no one owns the workflow.
Use a simple role model like this:
| Role | What this person owns during the pilot |
|---|
| Executive sponsor | Sets the business goal, approves the scope, makes the day-30 decision |
| Pilot operator | Reviews outputs daily, routes escalations, records misses, keeps the queue moving |
| Executive reviewer | Approves consequential drafts, tests whether the output is genuinely useful |
| Security / legal advisor | Confirms access and exclusions before launch, not after an incident |
| Vendor / internal builder | Fixes setup issues, templates, prompts, and integration problems without expanding scope |
The crucial rule is that the pilot operator must be real, named, and available. If no one owns the queue every business day, you are not running a pilot. You are running a demo with delayed cleanup.
A strong pilot says "no" early and clearly.
Exclude the following in most first-month pilots:
- autonomous outbound sending
- legal, finance, personnel, or board-sensitive workflows
- multi-executive rollout
- custom integrations that take longer to stand up than the pilot itself
- use cases whose success standard is still debated
That discipline follows Anthropic's advice: start simple, keep workflows predictable, and add complexity only when it demonstrably improves the outcome. If the team is still redesigning scope in week three, the charter was not tight enough.
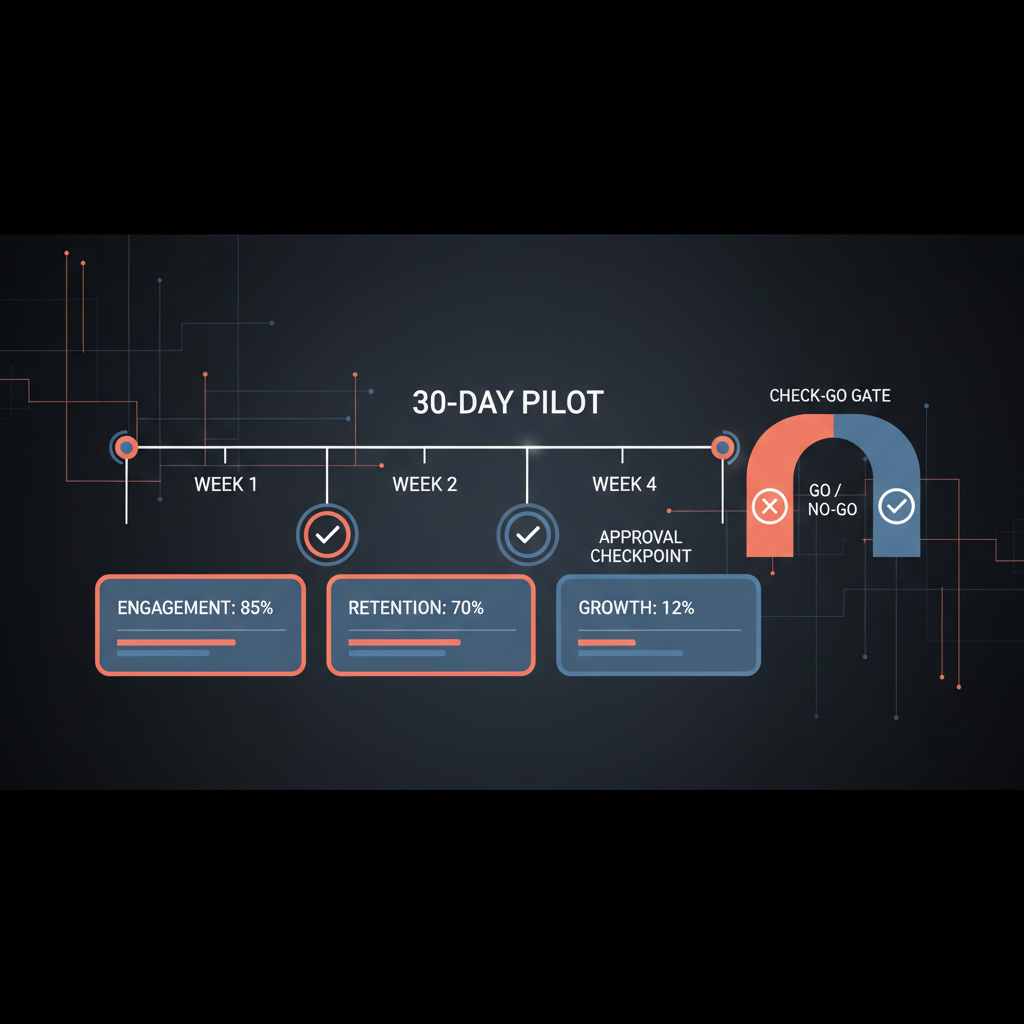
Treat the pilot like an operating review with four weekly stages.
| Week | Primary objective | What the team should do | What not to do |
|---|
| Week 1 | Stand up the operating model safely | Finalize scope, connect only required systems, define escalation categories, set the review window, confirm logging | Do not add "just one more workflow" because the demo looked promising |
| Week 2 | Prove basic reliability | Run the chosen workflows daily, review every output, capture misses and rewrites, confirm exclusions are holding | Do not excuse avoidable misses as "just AI being AI" |
| Week 3 | Tighten the workflow design | Improve templates, remove noisy fields, clarify reviewer ownership, refine escalation logic | Do not expand to another executive or team |
| Week 4 | Freeze scope and decide | Stop changing the setup, compile the evidence pack, run the go/extend/no-go review | Do not move the goalposts to save the pilot |
This cadence matters because many failed pilots are not model failures. They are management failures: no owner, no review rhythm, no frozen scope, and no actual decision date.
Month-one success depends less on clever prompting than on boring operational hygiene.
Use this checklist before launch:
| Implementation hygiene item | What "good" looks like |
|---|
| Access scope | Only required inbox, calendar, notes, or task systems are connected |
| Prompt and template control | Core prompts, brief formats, and draft templates are documented and versioned |
| Escalation tags | Sensitive topics and named stakeholders are labeled before the pilot begins |
| Approval path | Consequential outputs have one visible review route |
| Audit trail | The team can reconstruct what was drafted, edited, escalated, approved, and sent |
| Review windows | The operator and executive know exactly when queues will be cleared |
| Change control | Week-4 scope is frozen so the decision is based on comparable evidence |
This kind of hygiene is consistent with OpenAI's evaluation guidance and with governance principles in NIST's Generative AI Profile: constrain action space, observe the system, and keep accountability legible.
This article is not the finance guide, but the pilot still needs a small evidence pack.
At minimum, bring these questions to the day-30 review:
- Which workflows stayed in scope for the full month?
- Did the operator clear the queue consistently?
- Were sensitive items escalated correctly?
- Did reviewers treat outputs as usable drafts or as rewrite jobs?
- Would the office willingly continue the workflow with the current operating rules?
If you need the formula-based ROI model, cost structure, and reporting math, use the month-one ROI guide for that layer.
The pilot should end with one of three outcomes.
| Outcome | When it is justified | What to do next |
|---|
| Go | The workflows are stable, the review burden is manageable, and controls held under normal use | Expand carefully to adjacent workflows or a second executive office |
| Extend | The operating model shows promise, but one or two fixable issues still block scale | Run a short extension with narrower goals and a hard stop date |
| No-go | Review behavior is unstable, ownership is weak, or control failures keep recurring | Stop, document the reason, and avoid forcing scale |
Use this framework:
| Decision area | Go | Extend | No-go |
|---|
| Scope discipline | Charter held through day 30 | Minor drift but still recoverable | Scope changed so much the evidence is not trustworthy |
| Operator rhythm | Queue is cleared predictably | Rhythm exists but still fragile | Queue management is inconsistent or ownerless |
| Review burden | Review is fast enough to sustain | Review is still heavier than desired, but improving | Review is the new bottleneck |
| Risk control | Escalations and approvals work as designed | Controls need tightening but are fixable | Sensitive work is mishandled or routed inconsistently |
| Office willingness | The office wants to keep using the workflow | The office wants a limited second phase | The office does not trust or want the setup |
The most important rule is simple: do not redefine success in week four. A pilot is useful precisely because it forces the team to decide based on bounded evidence.
Most weak pilots fail for operational reasons, not because the category has no value.
The team tries to pilot email, calendar, research, travel, notes, and follow-ups at once. No one can tell what actually worked.
Outputs are generated, but no one owns the queue every business day. Then the team blames the product for a staffing problem.
Sensitive work enters the pilot too early, which turns every miss into a governance scare and slows learning on the safer workflows that could have produced signal.
Every miss triggers a new template, new use case, or new stakeholder. By week four, the team is comparing three different systems instead of one pilot design.
Month one is about proof. If you need a multi-executive rollout, long-term change management, or a service-model redesign, that is the next phase, not this one.
Do not run this style of pilot if:
- you cannot assign a real owner to review outputs every business day
- legal or security policy is unresolved on what the assistant may access
- the vendor requires heavy custom implementation before any useful workflow can be tested
- the real question is org redesign rather than a bounded buying decision
In those cases, the correct next step may be architecture review, policy design, or vendor narrowing first.
Usually two to four. Fewer can make the signal too thin, and more usually creates confusion and review fatigue.
Usually no. For serious buyers, month one should stay approval-first so the team can test quality and control separately from autonomy risk.
That is usually an extend, not a go. Fixable workflow-design issues deserve a short, tightly scoped extension. Repeated ownership or control failures usually do not.